
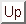

DLM in the form presented here is computationally expensive. We have
performed single recognition tasks with the complete system, but for
the experiments referred to in Table 3 we
have modified the system in several respects to achieve a reasonable
speed.
We split up the simulation into two phases. The only purpose of the
first phase is to let the attention blob become aligned with the face
in the input image. No modification of the connectivity was applied
in this phase, and only one average model was simulated. Its
connectivity 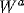 was derived by taking the maximum synaptic
weight over all real models for each link:
was derived by taking the maximum synaptic
weight over all real models for each link:
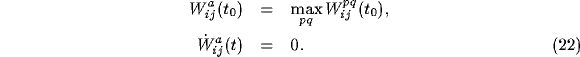
This attention period takes 1000 time steps. Then the complete
system, including the attention blob, is simulated, and the
individual connection matrices are subjected to DLM.
Neurons in the model layers are not connected to all neurons in the
image layer, but only to an 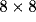 patch. These patches are
evenly distributed over the image layer with the same spatial
arrangement as the model neurons themselves. This still preserves full
translational invariance. Full rotational invariance is lost, but
the jets used are not rotationally invariant in any case.
The link dynamics is not simulated at each time step, but only after
200 simulation steps or 100 time units. During this time a running
blob moves about once over all of its layer, and the correlation is
integrated continuously. The simulation of the link dynamics is then
based on these integrated correlations, and since the blobs have
moved over all of the layers, all synaptic weights are modified.
For further increase in speed, models that are ruled out by the
winner-take-all mechanism are no longer simulated; they are just
set to zero and ignored from then on (
patch. These patches are
evenly distributed over the image layer with the same spatial
arrangement as the model neurons themselves. This still preserves full
translational invariance. Full rotational invariance is lost, but
the jets used are not rotationally invariant in any case.
The link dynamics is not simulated at each time step, but only after
200 simulation steps or 100 time units. During this time a running
blob moves about once over all of its layer, and the correlation is
integrated continuously. The simulation of the link dynamics is then
based on these integrated correlations, and since the blobs have
moved over all of the layers, all synaptic weights are modified.
For further increase in speed, models that are ruled out by the
winner-take-all mechanism are no longer simulated; they are just
set to zero and ignored from then on (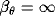 ).
The CPU time needed for the recognition of one face against a gallery
of 111 models is approximately 10--15 minutes on a Sun SPARCstation
10-512 with a 50 MHz processor.
).
The CPU time needed for the recognition of one face against a gallery
of 111 models is approximately 10--15 minutes on a Sun SPARCstation
10-512 with a 50 MHz processor.
In order to avoid border effects, the image layer has a frame with a width of 2 neurons without any features or connections to the model layers. The additional frame of neurons helps the attention blob to move to the border of the image layer. Otherwise, it would have a strong tendency to stay in the center.