

Next: Technical Aspects
Up: Experiments
Previous: Experiments
As a face data base we used galleries of 111 different persons. Of
most persons there is one neutral frontal view, one frontal view of
different facial expression, and two views rotated in depth
by 15 and 30 degrees respectively. The neutral frontal views serve as a model
gallery, and the other three are used as test images for recognition.
The models, i.e., the neutral frontal views, are represented by
layers of size 10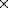 10 (see Figure 1).
Though the grids are rectangular and regular, i.e., the spacing
between the nodes is constant for each dimension, the graphs are
scaled horizontally in the x- and vertically in the y-direction
and are aligned manually: The left eye is always represented by the
node in the fourth column from the left and the third row from the
top, the mouth lies on the fourth row from the bottom, etc. The
x-spacing ranges from 6.6 to 9.3 pixels with a mean value of 8.2
and a standard deviation of 0.5. The y-spacing ranges from 5.5 to
8.8 pixels with a mean value of 7.3 and a standard deviation of
0.6. An input image of a face to be recognized is represented by a
16
10 (see Figure 1).
Though the grids are rectangular and regular, i.e., the spacing
between the nodes is constant for each dimension, the graphs are
scaled horizontally in the x- and vertically in the y-direction
and are aligned manually: The left eye is always represented by the
node in the fourth column from the left and the third row from the
top, the mouth lies on the fourth row from the bottom, etc. The
x-spacing ranges from 6.6 to 9.3 pixels with a mean value of 8.2
and a standard deviation of 0.5. The y-spacing ranges from 5.5 to
8.8 pixels with a mean value of 7.3 and a standard deviation of
0.6. An input image of a face to be recognized is represented by a
16 17 layer with an x-spacing of 8 pixels and a
y-spacing of 7 pixels. The image graphs are not aligned, since
that would already require recognition. The variations of up to a
factor of 1.5 in the x- and y-spacings must be compensated for
by the DLM process.
17 layer with an x-spacing of 8 pixels and a
y-spacing of 7 pixels. The image graphs are not aligned, since
that would already require recognition. The variations of up to a
factor of 1.5 in the x- and y-spacings must be compensated for
by the DLM process.
Next: Technical Aspects
Up: Experiments
Previous: Experiments