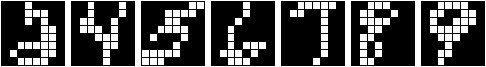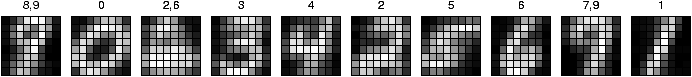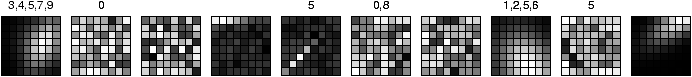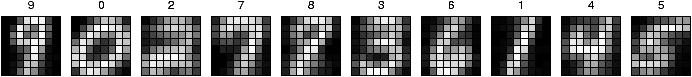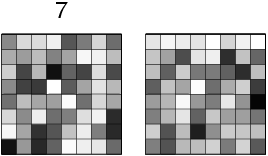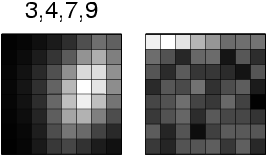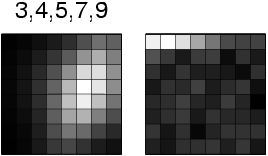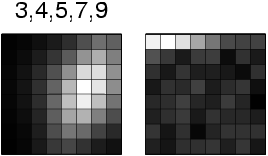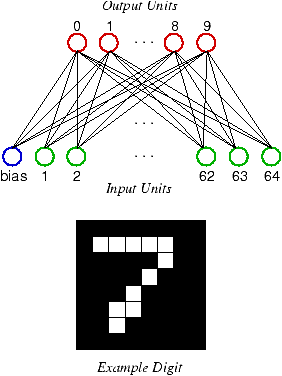
Figure 1: The architecture of the competitive learning
network. The binary activations from the 8×8 input
pattern consisting of 64 pixels are fed to the input units of the
network, which also contains a bias unit. The 10 output units each
correspond to a classification of the input as one of the 10
digits; the one with the highest activation is chosen as the
answer of the network. During training, the weights of this unit
are adjusted towards the input pattern, making that unit more
likely to win similar patterns in the future.