Archive of papers related to this topic
Archive of papers on all game-playing topics
Background
The Legion II Game
 The Legion II game is a test bed for a multi-agent architecture
called an
Adaptive Team of Agents (ATA).
The Legion II game is a test bed for a multi-agent architecture
called an
Adaptive Team of Agents (ATA).
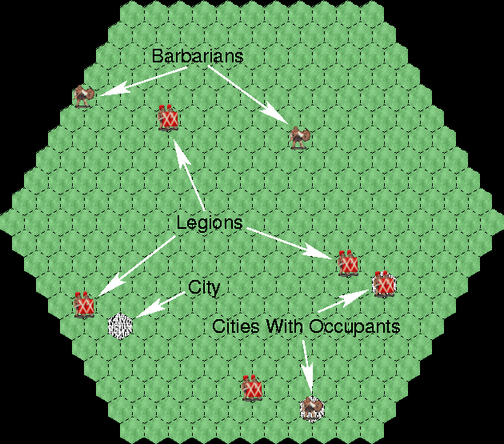
The game requires a handful of legions to defend a province of the Roman empire from pillage by an influx of randomly appearing barbarian warbands. Legions and warbands are shown iconically by one or two individuals of their type, in the tradition of the Civilization game genre (right).
Legion II is a discrete-state game. The map is tiled with hexagonal cells to discretize the locations of the game objects. The game is played in turns. Each legion or warband makes one atomic move during its turn, i.e. it moves to one of the six adjacent map cells or else remains stationary.
One new warband is placed in a random unoccupied location at the beginning of each turn. At the end of each turn, each barbarian collects 100 "points" of pillage if it is in a city, or 1 point otherwise. The pillage accumulates over the course of the game.
The legions can minimize the pillage by garrisoning the cities and/or eliminating the barbarians chess-style, by moving into the cells they occupy. The barbarians can only hurt the legions by running up the amount of pillage collected over the course of the game. At the end of a game that amount is the legions' score, expressed as a percentage of the maximum amount the barbarians could have collected in the absence of any legions. (Thus lower scores are better for the legions.)
The barbarians are pre-programed to approach the cities and flee the legions,
with a slight preference for the former so that they will take risks in order
to maximize the amount of pillage they inflict on the province.
The legions' behavior is learned; they are trained with a machine learning
methodology called
neuroevolution.
A separate sensor array is used for each class of object (legion, barbarian,
or city).
Additional details of the legions' sensors are given in
this paper.
The legion's sensors are interpreted by an artificial neural network,
which maps its sensory inputs onto a choice of one of the discrete
actions the legion can take in its turn.
Each turn the sensor values are calculated and propagated through the network,
and the action associated with the network's output unit with the highest
activation value is chosen as the legion's move for that turn.
These neural network controllers are trained by neuroevolution in order to
train the legions.
Neuroevolution is the use of a genetic algorithm to train an artificial
neural network.
For Legion II, a network to be evaluated is used to control the legions
over the course of an entire game.
At the end of the game, the game score is recorded as the network's
evolutionary fitness.
(Due to the scoring method, lower scores indicate higher fitness.)
Many games must be played during each evolutionary generation in order
to evaluate the fitness of all the networks in the population.
(Actually, the neurons in the networks are evaluated individually, using
a neuroevolutionary method called Neuroevolution with Enforced Sub-Populations, or ESP.)
Training is acclerated by turning off the graphical display during training;
the screenshots and movies are obtained by testing the trained networks
with a program that does display the graphics.
An Adaptive Team of Agents
(ATA) is a multi-agent architecture where the agents are homogeneous (i.e.
they all have the same capabilities and controller policies), but are capable
of adopting different behaviors.
That behavior requires a self-organized division of labor based on the
task, the environment, and the number of agents present.
In the Legion II game the ATA is enforced by using the same controller
network for each legion in the game.
The game is parameterized to require a division of labor for optimal
performance: there are five legions, but only three cities, so the team can
garrison all the cities to prevent the most expensive pillage, and still
have two legions free to chase and eliminate barbarians in the countryside.
Without an active division of labor – e.g. if three legions occupy
the cities and the other two sit idle for lack of a city to garrison –
then the number of barbarians in the game builds up over the course of the
game, filling the map and inflicting a great amount of pillage on the
countryside.
With suitable training the legions do learn the division of labor, and
are able to eliminate most of the accumulating barbarians while still
guarding the cities.
At the end of training the barbarians have learned the necessary division of
labor, so that they simultaneously defend the cities and mop up barbarians
in the countryside.
Movie: (3:47, 200 game turns)
Note: The oscillating behavior is cleaned up in the next solution,
and after that an examination of the run-time division of labor continues,
using the cleaned-up solution.
For Legion II, training examples were created by adding a
user interface, playing some example games with a human controlling
the legions, and recording the move that the human selected for each
sensory input encountered over the course of those games.
Then agents were trained again using lamarckian neuroevolution, so
that the examples would "guide" evolution to a solution wherein the
legions behaved similarly to the behavior used by the player when
generating the examples.
As a result, the legions learned to act according to an operational
doctrine that is more convincingly intelligent to an observer.
Notice that the test games use different map set-ups than the games used
to generate the examples. The legions learn to generalize from the example
behavior to qualitatively similar behavior on different maps, rather than
simply memorizing the examples.
Movie: (4:59, 200 game turns)
A roving legion to the west of the new city "notices" it, or the growing
crowd of barbarians around it, so it moves over, eliminates some of the
barbarians, enters the city, and remains fixed there for the rest of the
game in accord with the L0 doctrine.
The second rover continues to operate normally; the 3:2 division of labor
has become a 4:1 division of labor.
Since there is only one rover during the second half of the game, more
barbarians accumulate on the map than in the other examples.
Movie: (5:35, 200 game turns)
The resulting learned behavior looks very similar to the behavior obtained
by unguided evolution, except that the garrisons behave for the most part
according to the L1 doctrine – the unmotivated oscillations in and
out of the cities have been almost completely suppressed.
Movie: (4:13, 200 game turns)
A further requirement of the L1 strategy is a safety condition,
namely that a garrison should never leave a city if there is more
than one barbarian adjacent to it.
Otherwise, when the legion moves out to bump off one of the adjacent
barbarians, one of the others will move in and inflict 100 points of
pillage before the legion gets another move.
That safety condition was also learned by the legions shown in the movie
above.
Again they make a few errors, but there are several very clear examples
of behavior according to the safety condition in the movie.
For example, about half-way through the movie (time 1:56) the legion in
the rightmost city is locked in by several barbarians.
The garrison sits patiently for several turns until a roving legion
approaches and disperses them.
But the instant the rover has eliminated all but one of the barbarians
adjacent to the city, the garrisoning legion moves out to eliminate
it, as it should according to the L1 doctrine.
However, it is possible to use a learning method called stochastic sharpening
to train an agent's controller to produce utility confidence values at its
outputs.
That is, the outputs are activated to a level proportional to how good the moves
they represent are, in the controller's best estimate.
Such a controller can be used to pick the 5% random moves with a biased probability,
so that the ones with higher utility confidence values are more likely to be
chosen than the others.
The resulting control policy allows the agents to perform better at their
assigned task than when unbiased random selections are used, as described in
this paper.
The result holds for parameterized amounts of randomness up to at least 15%.
Movie: (3:47, 200 game turns)
Sensors, Controllers, and Training in the Legion II Game
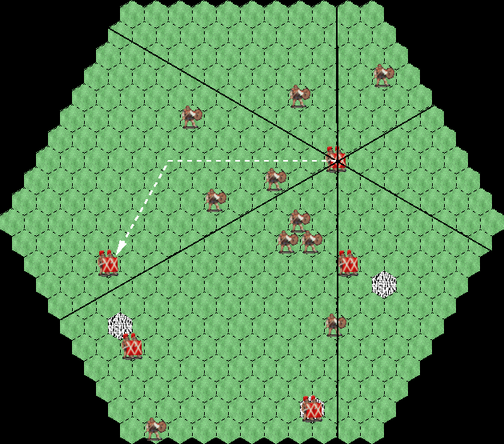 The legions are provided with sensors that give a fuzzy indication of the
number and distance to the various game objects.
The sensors divide the map into six "pie slices" centered on the legion's
own location (left), and detect the objects in each slice as the sum of
1/d for each object in the slice, where the distance d is the
number of cells that would have to be traversed to reach the object (white
arrow).
The legions are provided with sensors that give a fuzzy indication of the
number and distance to the various game objects.
The sensors divide the map into six "pie slices" centered on the legion's
own location (left), and detect the objects in each slice as the sum of
1/d for each object in the slice, where the distance d is the
number of cells that would have to be traversed to reach the object (white
arrow).
Adaptive Teams of Agents
Learning Progress
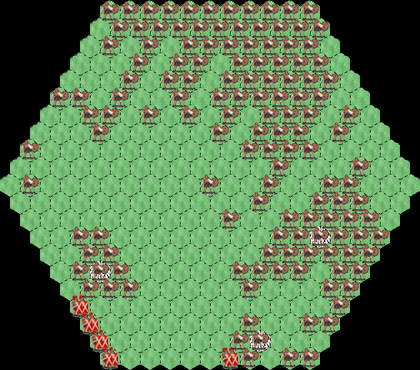 At the beginning of training the legions sit idle, move randomly, or drift
to the edge of the map and get stuck there, failing at both garrisoning the
cities and eliminating the build-up of barbarians.
At the beginning of training the legions sit idle, move randomly, or drift
to the edge of the map and get stuck there, failing at both garrisoning the
cities and eliminating the build-up of barbarians.
Movies
Example ATA solution to the Legion II game, evolved by unguided evolution:
 This solution was learned by ordinary neuroevolution, using the ESP
algorithm, with fitness determined by the play of complete games.
The division of labor is visible, and the team scores well, but the
legions serving as garrisons oscillate in and out of their cities
mindlessly when there are no barbarians nearby.
That sort of behavior is not convincingly intelligent to an observer.
This solution was learned by ordinary neuroevolution, using the ESP
algorithm, with fitness determined by the play of complete games.
The division of labor is visible, and the team scores well, but the
legions serving as garrisons oscillate in and out of their cities
mindlessly when there are no barbarians nearby.
That sort of behavior is not convincingly intelligent to an observer.
[4.0 MB AVI]
[4.0 MB WMV]
"L0" solution to the Legion II game, evolved by Lamarckian evolution:
Lamarckian evolution has only very limited capability in biological
evolution (e.g., epigenetic effects), but can be made to work well in
biologically inspired computational processes such as genetic algorithms.
For neuroevolution, if training examples are available, lamarckian
evolution can be implemented by training the networks in the
evolutionary population with a supervised learning method such as
backpropagation between each evolutionary fitness evaluation.
 For this solution the training examples were created by playing according
to a Level Zero (L0) operational doctrine, which requires a garrison
to remain permanently fixed in a city once it enters.
The division of labor is clearly visible, and the trained legions behave
in accord with the L0 doctrine used by the player while generating the
training examples. (In some runs the resulting controllers will make an
occasional error with respect to the L0 doctrine, but such mistakes are
rare.)
For this solution the training examples were created by playing according
to a Level Zero (L0) operational doctrine, which requires a garrison
to remain permanently fixed in a city once it enters.
The division of labor is clearly visible, and the trained legions behave
in accord with the L0 doctrine used by the player while generating the
training examples. (In some runs the resulting controllers will make an
occasional error with respect to the L0 doctrine, but such mistakes are
rare.)
[4.2 MB AVI]
[4.3 MB WMV]
Run-time Adaptation:
 In this experiment the "L0" solution described above is re-tested to show
that the 3:2 division of labor is not hardwired into the legions' brains.
Play begins and proceeds normally until the mid-point of the game (time 2:16),
at which time a fourth city is added in a random location to test the legions'
ability to re-adapt to the new situation.
In this run the city is placed on the northeastern edge of the map.
(See image at left.)
In this experiment the "L0" solution described above is re-tested to show
that the 3:2 division of labor is not hardwired into the legions' brains.
Play begins and proceeds normally until the mid-point of the game (time 2:16),
at which time a fourth city is added in a random location to test the legions'
ability to re-adapt to the new situation.
In this run the city is placed on the northeastern edge of the map.
(See image at left.)
[4.7 MB AVI]
[4.8 MB WMV]
"L1" solution to the Legion II game, evolved by Lamarckian evolution:
 For this solution the training examples were created by playing according
to a Level One (L1) doctrine, which allows a garrison to leave a city to
bump off an adjacent barbarian, but does not allow it to move any farther
than a cell adjacent to the city, and which also requires the garrison to
return to the city and remain fixed there whenever there is no adjacent
barbarian.
For this solution the training examples were created by playing according
to a Level One (L1) doctrine, which allows a garrison to leave a city to
bump off an adjacent barbarian, but does not allow it to move any farther
than a cell adjacent to the city, and which also requires the garrison to
return to the city and remain fixed there whenever there is no adjacent
barbarian.
[3.9 MB AVI]
[3.9 MB WMV]
Managed Randomization of Behavior:
Game agents controlled by AI tend to be very predictable, and players learn to
exploit that predictability.
One way of addressing that problem is to introduce some degree of randomness
into the game agents' moves.
For example, you could program an agent to do what its controller specifies
only 95% of the time, and do something else at random the other 5% of the time.
That will, of course, reduce the agent's performance of its assigned task.
 This solution shows the behavior of the Legion II agents when 5%
biased randomness is introduced after training with stochastic sharpening.
The legions can sometimes be seen to make obvious mistakes, but they still
manage to score better than when unbiased randomness is used.
This solution shows the behavior of the Legion II agents when 5%
biased randomness is introduced after training with stochastic sharpening.
The legions can sometimes be seen to make obvious mistakes, but they still
manage to score better than when unbiased randomness is used.
[4.0 MB AVI]
[4.0 MB WMV]